Conversione da analogico a digitale. File compresso o non compresso?
Come trasformare un’onda sonora del nostro parlato, musica o altro in file digitale? Come fare? É meglio un file compresso, con o senza perdita di dati (lossy o lossless) o uno non compresso?
Sommario
La conversione
L’apparecchio che svolge questo lavoro è quel che normalmente viene definita “scheda audio”. Questa è formata da un convertitore “Analogico – digitale” e “Digitale – analogico” perché dobbiamo trasformare un segnale udibile dalle nostre orecchie (il suono) ad un segnale digitale formato da una serie di 1 e 0, molto familiare per il computer ma inaudibile per gli umani. Questo segnale viene elaborato, variando il volume, l’equalizzazione, la dinamica, l’inserimento di vari filtri e tagli, per poi ritrasformarlo in analogico per poter essere udibile. Non me ne vogliano i tecnici per questa mia descrizione “elementare” ma probabilmente capibile a tutti.
La quantizzazione
Ora scendiamo un po’ nei particolari.
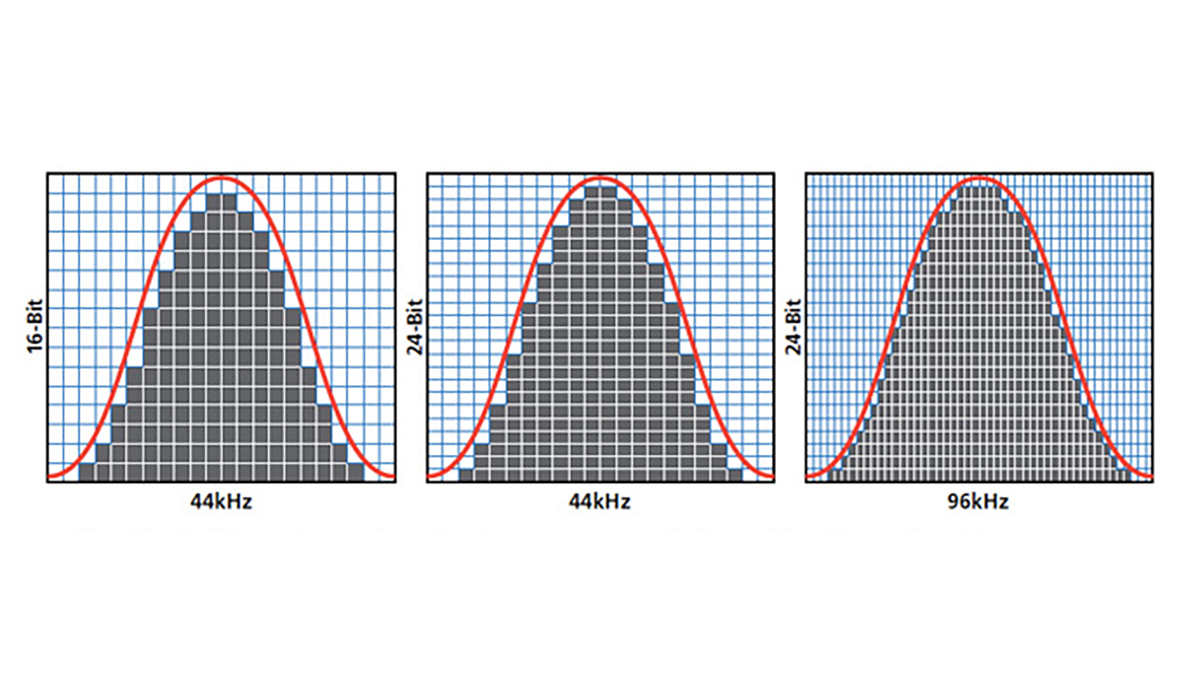
Quantizzazione e numeri di bit
La quantizzazione, espressa in frequenza di campionamento, descrive il numero dei campioni in cui è stata suddivisa l’onda sonora nell’unità di tempo.
Per convertire l’audio in codice binario, sono necessari decine di migliaia di campionamenti (samples) per secondo, così da costruire un’immagine “approssimativa” dell’onda analogica.
Approssimativa è perché nella grandezza del campionato, l’onda ha un suo punto iniziale e uno finale, ma per il campionamento è unico e lo calcola come una media tra l’inizio e la fine dell’onda. Più il campionamento è alto (numero di campioni al secondo) e più la grandezza dell’onda campionata è piccola e meno è la differenza tra il punto iniziale e quello finale dell’onda.
Facendo un esempio di un campionamento comune, quello del CD, ovvero 44,1kHz cioè suddividere l’onda di 1 secondo in 44100 spezzoni. Ad ogni spezzone gli viene attribuito un numero a 16 bit
Prima di approfondire con dati numerici, facciamo un esempio con la “campionatura” di un’immagine (forse più comune anche per la familiarizzazione con le foto con i cellulari).
Un’immagine è formata da un numero di Pixel in altezza e larghezza del sensore fotografico che la campiona. In pratica, è la misura che descrive la dimensione fisica delle immagini digitali bitmap (come le conosciamo). Ogni pixel “campionato” gli viene assegnato una serie di numeri binari.
Un’immagine è formata da n. Pixel (campionamenti per l’audio) in un’unità di superfice Inch – pollice (il secondo per l’audio). Quindi più pixel sono contenuti nell’unità di misura, più l’immagine è definita. Ad ogni pixel viene attribuito un dato e in base ai quanti bit è formato il dato ha più informazioni. Ad esempio, una profondità a 2 bit può memorizzare solo nero, bianco e due tonalità di grigio (ma il valore più comune è 8 bit). I valori crescono esponenzialmente: così, per esempio, con una foto a 8 bit (2 alla potenza di 8 = 256) avrete 256 toni di verde, 256 toni di blu e 256 toni di rosso (RGB), che significa circa 16 milioni di colori. Questo è già più di ciò che l’occhio umano può distinguere, quindi un’immagine a 16-bit o 32-bit apparirà relativamente simile a ciò che il nostro occhio può vedere. Naturalmente, questo significa che l’immagine sarà più pesante in termini di dimensione, perché ci sono più informazioni contenute in ogni pixel. Quindi riepilogando, per frequenza di campionamento si intende quante volte al secondo, durante il processo di digitalizzazione venga prelevato un campione del segnale originale. Ovviamente maggiore risulterà questa frequenza, maggiore sarà la ricostruzione dinamica in digitale del segnale originale, in altre parole la fedeltà. Allo stesso modo maggiore sarà il numero di bit (Bit depth o profondità di Bit), maggiore sarà l’accuratezza descrittiva del segnale (in altre parole la risoluzione), disponendo di una maggiore quantità di bit di informazioni presenti per ogni campione rilevato. Risulta pertanto evidente il salto qualitativo che possa intervenire nella riproduzione di un segnale audio che porti con sé una dotazione di informazioni di 32 bit rispetto ad uno di “soli” 16 bit.
Se registriamo la voce a 192 kHz e 32 bit risulterà al nostro orecchio migliore del 44,1 kHz e 16 bit? No non noteremo differenza da un punto di vista auditivo, ma noteremo una grande differenza in ordine di peso. Quindi conviene avere un file così pesante se non abbiamo differenze qualitative? Ovviamente, se il campionamento da scegliere è per una registrazione di un brano in uno studio di registrazione, allora la scelta deve ricadere sul campionamento più alto.
Quale frequenza di campionamento dobbiamo scegliere per la registrazione della nostra voce per il podcast, per lo spot pubblicitario o l’audio libro? Si può seguire una semplice regola, senza andare in formule matematiche, ovvero “Per avere una codifica digitale di un segnale analogico accurata, la frequenza di campionamento deve essere almeno il doppio della frequenza massima da campionare.” Non prendiamo in considerazione lo spettro della voce, che non va oltre i 2/3 kHz, ma prendendo l’intero spettro auditivo umano, che in rari casi arriva a 20kHz, potremmo usare come frequenza di campionamento lo standard usato per i CD ovvero 44,1 kHz e 16 bit, o in alternativa 48kHz e 16 bit (per problemi si sinconizzazione per i video).
File compresso o no
Il file audio compresso ci permette di ridurre notevolmente la dimensione, compromettendo la qualità del suono (non sempre udibile per orecchie non esperte) rispetto al file non compresso, ma alcune volte dobbiamo trovare il giusto compromesso in base alle necessità. Vediamo le differenze.
Pro e contro
Prima di vedere i pro e contro dei file compressi, dobbiamo puntualizzare alcune cose. La prima è quella che se dobbiamo trattare un file audio per delle lavorazioni (equalizzazioni, dinamiche, volumi ecc.) è sempre consigliabile lavorare un file non compresso perché in ogni lavorazione e successivo salvataggio abbiamo sempre tutti i dati. Salvare più volte un file compresso è come comprimerlo e quindi tagliare parti di esso ogni volta. Lavorare con un file non compresso ci comporta un utilizzo maggiore di spazio, ma siamo sicuri di aver un suono con tutte le informazioni che ci servono. Se questo deve essere poi esportato per apparecchiature dove, per risparmi di banda, effettuano già loro dei tagli, allora potremmo comprimerli, ma sempre conservando il file non compresso. Prendiamo per esempio la “Radio FM” dove vengono tagliate le frequenze superiori a 14 kHz, quando le frequenze auditive vanno da 20 a 20.000 Hz. Ci sono musiche che devono essere diffuse in centri commerciali o in luoghi dove non abbiamo delle casse acustiche che riescono a coprire l’intera gamma (vedi piccoli altoparlanti collocati nel controsoffitto) ed allora la compressione è giustificata perché non ci accorgeremo della differenza.
Tipologie
File senza compressione
- File che non ha subito nessun tipo di compressione
Compressione con perdita dati o lossy
- quando l’informazione contenuta nel file compresso è minore di quella contenuta nel file di origine, questa permette file di dimensioni ridotte, ma a scapito della qualità.
Compressione senza perdita dati o lossless
- quando l’informazione contenuta nel file compresso è identica a quella contenuta nel file di origine, e dal file compresso si può riottenere l’intera informazione contenuta nel file originale pur da un file di dimensioni minori.
Comprimere un file audio con perdita dati genera un file con dimensioni molto piccole (si può raggiungere un rapporto fino 10 a 1). Uno degli algoritmi di compressione più usati è il .mp3. Questo non è dei migliori (vista anche l’età) ma è il più diffuso. I parametri usati per una discreta qualità sono di 128 Kbit/s (si può arrivare fino a 384 kbit/s), ma può essere utile solo se, dopo diverse lavorazioni del file non compresso, ci occorre un file di dimensioni ridotte (più i Kbit/s sono alti più pesa il file).
L’algoritmo di compressione MP3 (Moving Picture Expert Group-1/2 Audio Layer 3) è un processo con perdita di dati, rimuovendo delle informazioni dal file di origine. Oggi, gli algoritmi più efficienti, eliminano quelle frequenze che l’orecchio umano percepisce meno.
Gli algoritmi di compressione
Compressione con perdita dati
- AAC simile al mp3, quindi con perdita dati ma con una qualità migliore, studiato dalla Apple
- OGG Vorbis alternativa al mp3 e AAC e libera da vincoli brevettuali
- MP3 garantisce dimensioni ridotte dei file a discapito della qualità. Molto utilizzato su smartphone e altri dispositivi mobile ed è molto diffuso.
Compressione senza perdita dati
- FLAC algoritmo di compressione senza perdita dei dati, occupa circa metà dello spazio del file non compresso, esente da brevetti ed è il più usato per lo stoccaggio dei file musicali senza occupare tanto spazio. Unica pecca è che non è supportato da Apple.
- MQA utilizzato per gli streaming ad alta risoluzione
- ALAC (Apple Lossless Audio Codec) è un codec audio sviluppato da Apple Inc. allo scopo di ottenere una compressione lossless, molto simile (praticamente uguale) al FLAC ma con marchio Apple.
File senza compressione
- PCM (Pulse-code modulation) è il formato audio dove la conversione nel file digitale è fedele all’audio analogico. I formati audio più comuni dei file PCM sono WAV e AIFF
- WAV (Waveform Audio File Format) è un formato molto usato, sviluppato da Microsoft e IBM e ha un’ottima qualità sonora, ma ha uno scarso supporto dei metadati.
- AIFF (Audio Interchange File Format) è l’alternativa Apple al file Wav e contrariamente a quest’ultimo supporta meglio i metadati
Cosa sono i metadati
Abbiamo parlato di metadati, ma cosa sono? Sono delle informazioni “nascoste” nel file contenenti una serie di informazioni utili, come il nome dell’artista, il titolo dell’album, il titolo del brano, l’anno, la traccia, il genere ecc., tutte informazioni molto utile per la catalogazione dei brani. É possibile leggere ed inserire questi dati con diversi software in commercio, c’è n’è uno free, che uso da tempo, facile ed intuitivo, si chiama Mp3Tag ed è possibile scaricarlo anche in lingua italiano.